# download kubebuilder and extract it to tmp curl -sL https://go.kubebuilder.io/dl/2.0.0-beta.0/${os}/${arch} | tar -xz -C /tmp/ # move to a long-term location and put it on your path # (you'll need to set the KUBEBUILDER_ASSETS env var if you put it somewhere else) mv /tmp/kubebuilder_2.0.0-beta.0_${os}_${arch} /usr/local/kubebuilder export PATH=$PATH:/usr/local/kubebuilder/bin
$ kubebuilder create api --group webapp --version v1 --kind Guestbook Create Resource [y/n] y Create Controller [y/n] y Writing scaffold for you to edit... api/v1/guestbook_types.go controllers/guestbook_controller.go Running make: $ make go: creating new go.mod: module tmp go: found sigs.k8s.io/controller-tools/cmd/controller-gen in sigs.k8s.io/controller-tools v0.2.5 /Users/dongzezhao/go/bin/controller-gen object:headerFile="hack/boilerplate.go.txt" paths="./..." go fmt ./... go vet ./... go build -o bin/manager main.go
API 创建完成后,在项目根目录下查看目录结构。
3.2 安装CRD
执行下面的命令安装 CRD
1 2 3 4 5 6
$ make install go: creating new go.mod: module tmp go: found sigs.k8s.io/controller-tools/cmd/controller-gen in sigs.k8s.io/controller-tools v0.2.5 /Users/dongzezhao/go/bin/controller-gen "crd:trivialVersions=true" rbac:roleName=manager-role webhook paths="./..." output:crd:artifacts:config=config/crd/bases kustomize build config/crd > crd.yaml $ kubectl create -f crd.yaml
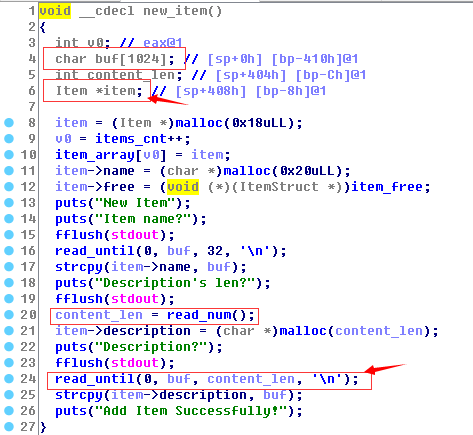
由于接触堆漏洞时间短,没有大量训练,解决这道题时遇到各种坑,记录下体会。首先,一开始发现了栈溢出,但是没想到如何利用,就忘记了,忘记了。然后发现Use after free可以泄漏地址,但只泄漏了fast bin中堆基址,而没想到泄漏unsorted bin中libc地址。与此同时,发现可以Double free,就一直在想如何构造伪块,利用Large bin attack覆盖tls_dtors_list地址,但是strcpy复制输入数据到堆上时会截断NULL字节并且Large bin attack在当前版本的glibc(2.23)已经失效。尝试了几次,发现这条路走不通。我就重新认真思考,突然发现既然能泄漏堆块基址,就可以泄漏libc基址。当泄漏了libc基址和堆块地址,就在想如何覆盖free@got.plt,但是Large bin attack在当前版本glibc已经失效。然后在午睡的时候,突然灵光一闪,发现栈溢出这块还没有利用,认真分析了一下栈溢出可以覆盖的内容,发现可以通过覆盖栈上item地址,造成任意地址写。已经快接近成功了,但是由于程序开启的PIE导致代码段地址随机,无法获取free@got.plt地址。就在想如何泄漏text段地址,通过调试观察堆上内容,发现text段的item_free函数的地址存储在堆上。于是,通过任意地址写结合Use after free泄漏text段地址,从而获取free@got.plt地址,最终成功。 PS:我在Ubuntu14.04(glibc 2.19)上通过Overwriting tls_dtors_list可以利用成功,但是在打远程时由于tls_dtors_list地址偏移不一致,导致失败。
Large bin unlink: 利用方式在glibc 2.20版之后已经失效,但还是有必要介绍一下其中一些思路。该攻击最早出现在2014年Google Project Zero项目的一篇文章中The poisoned NUL byte, 2014 edition。在Linux堆漏洞之Double-free中已经讲过unlink宏,其中只讲到unlink Small bin时进行的操作,只需绕过第一层双向循环链表检查就可以利用unlink。如果unlink Large bin,由于Large bin块含有字段fd_nextsize和bk_nextsize,在绕过第一层双向循环链表检查还会进行第二次双向循环链表检查。但是在glibc早期版本(2.19之前),第二次双向循环链表检查只通过断言(assert)形式,属于调试信息,不能真正的对漏洞进行有效的防护。从而可以利用Large bin unlink导致一次任意地址写,然后利用overwriting tls_dtor_list实现漏洞利用。在程序main()函数结束调用exit()函数时,会遍历tls_dtor_list调用一些处理收尾工作的函数,如果通过overwriting tls_dtor_list使其指向伪造的tls_dtor_list,就可以调用自己的函数(如system(‘/bin/sh’))。在当前版本的glibc(2.23)中,unlink宏在unlink Large bin 时会进行双向链表检查,而且在__call_dtors_list中获取tls_dtor_list时也做了一些限制,导致很难利用Large bin unlink。 Overwriting tls_dtor_list是一个很好的利用点,但是目前我还没有找到如何利用。
利用堆块覆盖 这一类攻击主要是获取对目标堆块的读写,利用方式分两种情况:一种是覆盖最低字节为任意数(off-by-one overwrite freed or allocated),另一种是覆盖最低字节为NULL(off-by-one NULL byte)。
off-by-one overwrite freed or allocated : 如图1所示,堆块A、B、C,其中堆块A已分配且含有off-by-one漏洞,堆块B已释放,堆块C为目标堆块,需要对堆块C可读写。可以通过堆块A的off-by-one漏洞覆盖堆块B size字段的最低字节(不改变inuse位),使堆块B的长度可以包含堆块C。然后在malloc(B+C),就可以获取堆块B的原来指针,从而可以对目标堆块进行读写。 如果堆块A、B、C都是已分配,可以释放掉堆块B,将问题转化为前面一种情况,同样可以解决。
1 2 3 4 5 6
_____________________ ______|_____B_______|______ | | | | | | | | | | | A | B | C | | A | B1 | B2 | | C | |______|______|_______| |______|____|____|___|_____| 图1 overwrite freed or allocated 图2 overwrite null byte
基于fastbin块LIFO的特点,我们可以先申请,然后释放,再申请就可以得到原来地址的块。但是这不能满足我们的需求,我们需要在将堆分配在可控地址。我们可以通过堆溢出更改已经申请块的fd,使其指向我们可控的地址,并且在可控地址上伪造假的fastbin结构。然后释放,再申请两次,第2次就可以得到分配在可控地址上的块。(覆盖fd) 还有一种方法直接修改free函数的参数,使free函数的参数为可控地址,然后在可控地址上伪造假的堆块。(House of Spirit)
Return to dl-resolve是一种新的rop攻击方式,出自USENIX Security 2015上的一篇论文How the ELF Ruined Christmas。前段时间,学习了return to dl-resolve 方法,并且分别在32位应用和64位应用上实践了一番。网上有很多文章讲解return to dl-resolve的原理,现记录下我的学习心得,如有不对的地方,欢迎斧正。
0x01. dl-resolve解析原理
return to dl-resolve 主要是利用Linux glibc的延迟绑定技术(Lazy binding)。Linux下glibc库函数在第一次被调用的时候,才会去寻找函数的真正地址然后进行绑定。在这一过程中,主要由过程链接表(PLT)提供跳转到解析函数的胶水代码,然后将函数的真正地址回填到函数的全局偏移表中,再将控制权给需要解析的函数。
* Symbol table entry. */ typedefstruct { Elf32_Word st_name; /* Symbol name (string tbl index) */ Elf32_Addr st_value; /* Symbol value */ Elf32_Word st_size; /* Symbol size */ unsignedchar st_info; /* Symbol type and binding */ unsignedchar st_other; /* Symbol visibility */ Elf32_Section st_shndx; /* Section index */ } Elf32_Sym;
typedefstruct { Elf64_Word st_name; /* Symbol name (string tbl index) */ unsignedchar st_info; /* Symbol type and binding */ unsignedchar st_other; /* Symbol visibility */ Elf64_Section st_shndx; /* Section index */ Elf64_Addr st_value; /* Symbol value */ Elf64_Xword st_size; /* Symbol size */ } Elf64_Sym;
/* Sanity check that we're really looking at a PLT relocation. */ assert (ELFW(R_TYPE)(reloc->r_info) == ELF_MACHINE_JMP_SLOT);
/* Look up the target symbol. If the normal lookup rules are not used don't look in the global scope. */ if (__builtin_expect (ELFW(ST_VISIBILITY) (sym->st_other), 0) == 0) { conststructr_found_version *version =NULL;
if (l->l_info[VERSYMIDX (DT_VERSYM)] != NULL) { constElfW(Half) *vernum = (constvoid *) D_PTR (l, l_info[VERSYMIDX (DT_VERSYM)]); ElfW(Half) ndx = vernum[ELFW(R_SYM) (reloc->r_info)] & 0x7fff; version = &l->l_versions[ndx]; if (version->hash == 0) version = NULL; }
/* We need to keep the scope around so do some locking. This is not necessary for objects which cannot be unloaded or when we are not using any threads (yet). */ int flags = DL_LOOKUP_ADD_DEPENDENCY; if (!RTLD_SINGLE_THREAD_P) { THREAD_GSCOPE_SET_FLAG (); flags |= DL_LOOKUP_GSCOPE_LOCK; }
/* Currently result contains the base load address (or link map) of the object that defines sym. Now add in the symbol offset. */ //将要解析的函数的偏移地址加上libc基址,就可以获取函数的实际地址 value = DL_FIXUP_MAKE_VALUE (result, sym ? (LOOKUP_VALUE_ADDRESS (result) + sym->st_value) : 0); } else { /* We already found the symbol. The module (and therefore its load address) is also known. */ value = DL_FIXUP_MAKE_VALUE (l, l->l_addr + sym->st_value); result = l; }
/* And now perhaps the relocation addend. */ value = elf_machine_plt_value (l, reloc, value);
//将已经解析完的函数地址写入相应的GOT表中 if (sym != NULL && __builtin_expect (ELFW(ST_TYPE) (sym->st_info) == STT_GNU_IFUNC, 0)) value = elf_ifunc_invoke (DL_FIXUP_VALUE_ADDR (value));
/* Finally, fix up the plt itself. */ if (__glibc_unlikely (GLRO(dl_bind_not))) return value;